Are you hearing complaints about "GPU costs are too high" in AI development environments? The reality is that many enterprise Kubernetes AI workloads operate with GPU utilization rates of just 20-30%. This represents a classic example of "money-burning" infrastructure due to static resource allocation.
However, the CNCF Annual Cloud Native Survey (2026) reports that 82% of organizations use Kubernetes in production environments, with 66% leveraging Kubernetes for AI inference workloads. In other words, Kubernetes has already become the "de facto operating system" for the AI era.
This article explores the latest techniques for achieving 50-70% AI infrastructure cost reduction through dynamic resource management with Kubernetes Dynamic Resource Allocation (DRA).
The GPU Crisis in the AI Era—20% Utilization Rate 'Money-Burning' Infrastructure
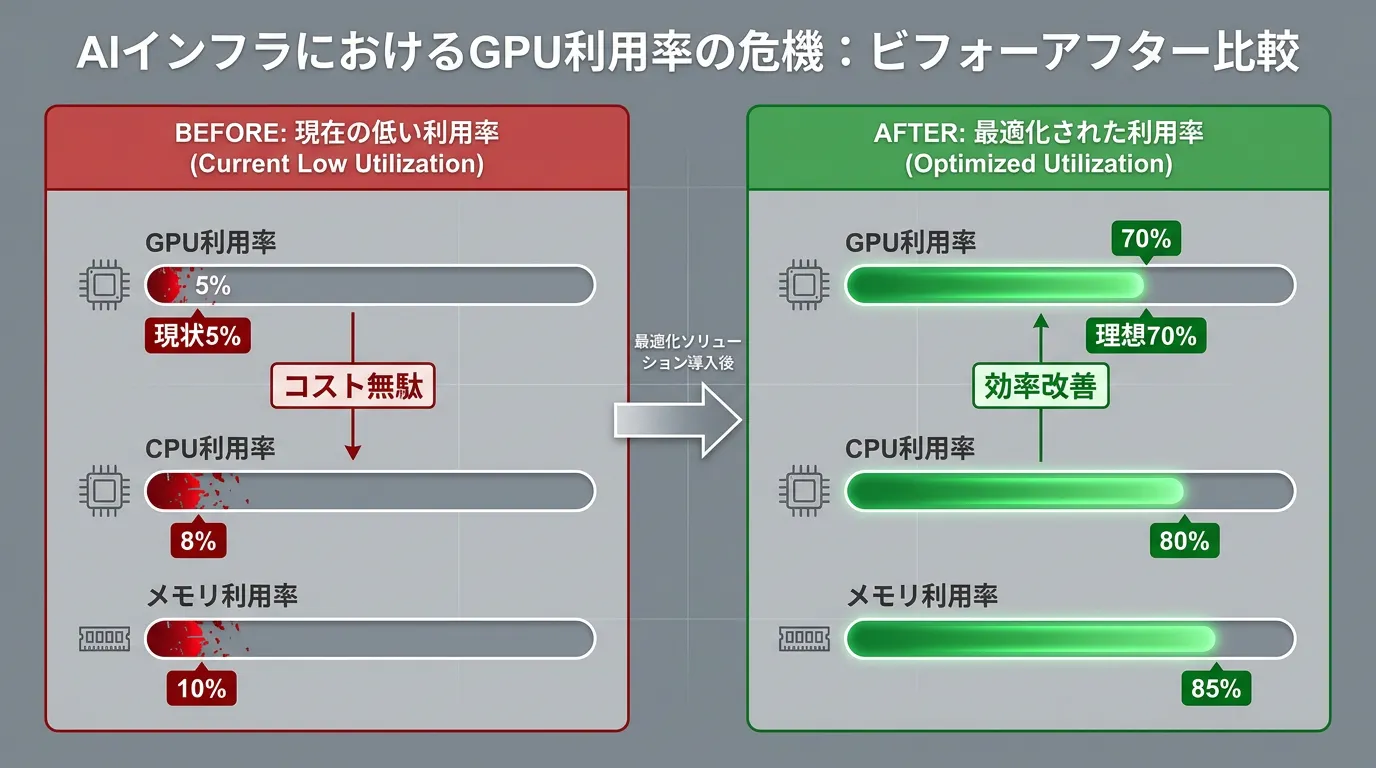
The reality of GPU utilization in AI/ML workloads is more severe than imagined. According to Cast AI's 2026 study, analysis of 23,000 Kubernetes clusters reveals that GPU utilization averages just 5%, with CPU utilization at 8% (down from 10% the previous year).
Limitations of Static Resource Allocation
Traditional Kubernetes has primarily used the "Device Plugin" approach for static GPU resource allocation. This method has revealed the following challenges:
- Over-provisioning: CPU over-provisioning surged from 40% to 69% year-over-year
- Resource lock-in: Once allocated, GPUs cannot be shared across other workloads
- Coarse granularity: Only full GPU allocation possible, no subdivision by memory capacity or compute capability
- High adjustment costs: Manual adjustments required for workload fluctuations
Cost Pressure Reality
AWS has increased H200 Capacity Block prices by 15% in January 2026, and bearing these high costs with 5% utilization significantly deteriorates enterprise AI investment ROI.
The fundamental resource efficiency problem underlies why many companies conclude that "AI projects don't justify their costs." To achieve cost optimization, organizations must transition from traditional static allocation to dynamic resource management. As a solution to this challenge, managed Kubernetes platforms like Kubo are working on automating resource optimization through AI-Driven Deployment.
Kubernetes Dynamic Resource Allocation (DRA) Transforms Next-Generation GPU Management
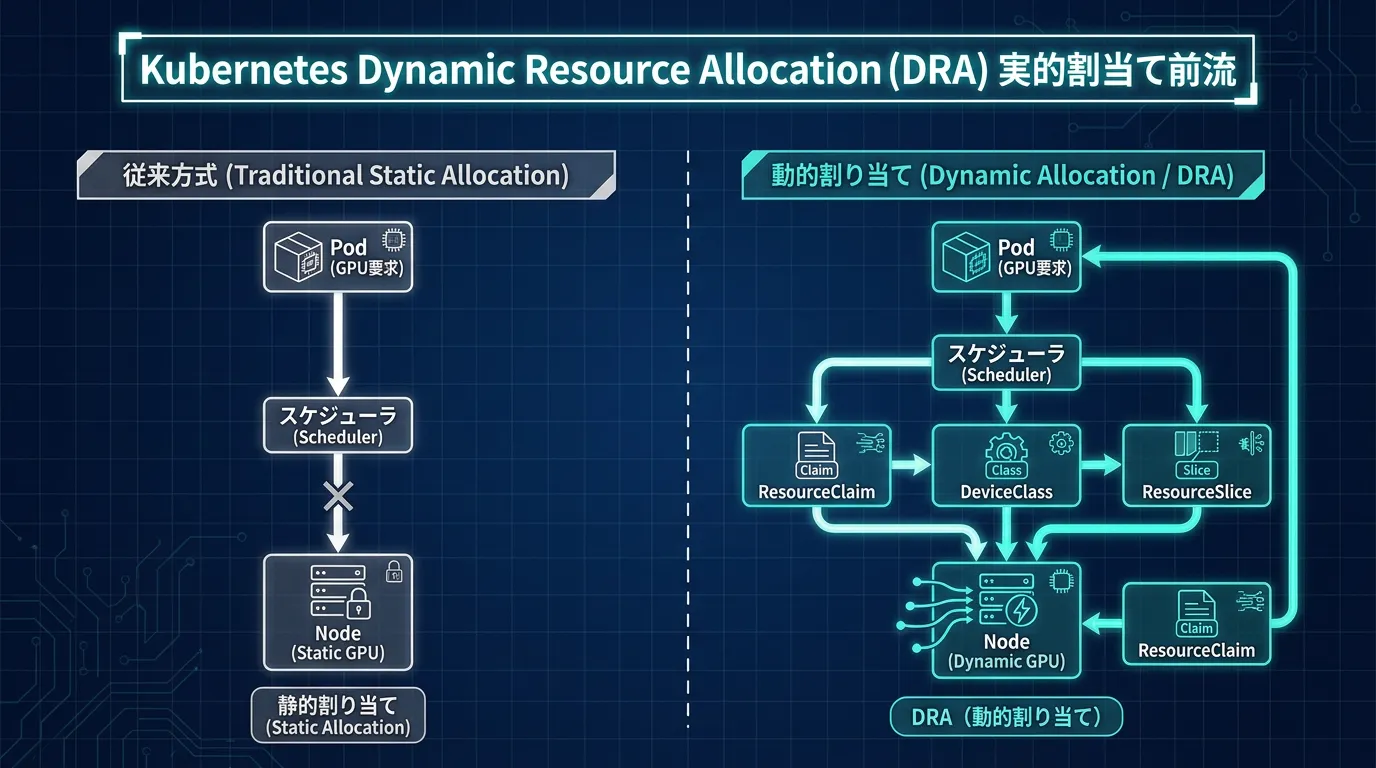
Kubernetes Dynamic Resource Allocation (DRA), which reached GA (General Availability) in Kubernetes 1.34, represents an innovative approach that replaces the traditional static Device Plugin method.
DRA's Three Core Innovations
1. Declarative Resource Specification
Instead of requesting "2 GPUs," DRA enables specification of concrete requirements like "GPU memory 8GiB or higher, CUDA Compute Capability 8.0 or higher" using Common Expression Language (CEL):
apiVersion: resource.k8s.io/v1
kind: ResourceClaim
metadata:
name: ai-gpu-claim
spec:
deviceClassName: high-performance-gpu
devices:
requests:
- name: training-gpu
selectors:
- matchExpressions:
- name: memory
operator: Gt
values: ["8Gi"]
- name: compute-capability
operator: Gte
values: ["8.0"]
2. Device Sharing and Pooling
Multiple containers or Pods can reference the same ResourceClaim, enabling GPU partitioning. For inference workloads, this allows efficient GPU sharing across multiple models.
3. Centralized Management
Centralized device categorization through DeviceClass enables cluster administrators to pre-define optimal device configurations for different workload types.
Key Differences from Traditional Methods
| Aspect | Device Plugin (Traditional) | DRA (New Method) |
|---|---|---|
| Resource Specification | Quantity-based (2 GPUs) | Capability-based (8GiB+ memory) |
| Device Sharing | Not supported | Supported |
| Dynamic Optimization | Manual adjustment required | Automatic optimal placement |
| Granularity | GPU unit | GPU internal resource unit |
Proven Results: 70-80% GPU Utilization with 50-70% Cost Reduction
An increasing number of companies are achieving significant cost reductions through DRA technology implementation.
Dramatic Utilization Improvement Results
Forward-thinking companies are achieving 70-80% GPU utilization through DRA-based dynamic resource management, a substantial improvement from the previous 20-30%. This results from the following technical improvements:
Automatic Resource Adjustment
- Real-time GPU allocation based on workload demand
- Minimized idle time
- Efficient GPU sharing across multiple workloads
Intelligent Scheduling
- Kubernetes scheduler references ResourceSlice for automatic optimal node placement
- Placement optimization considering device characteristics (memory capacity, compute performance)
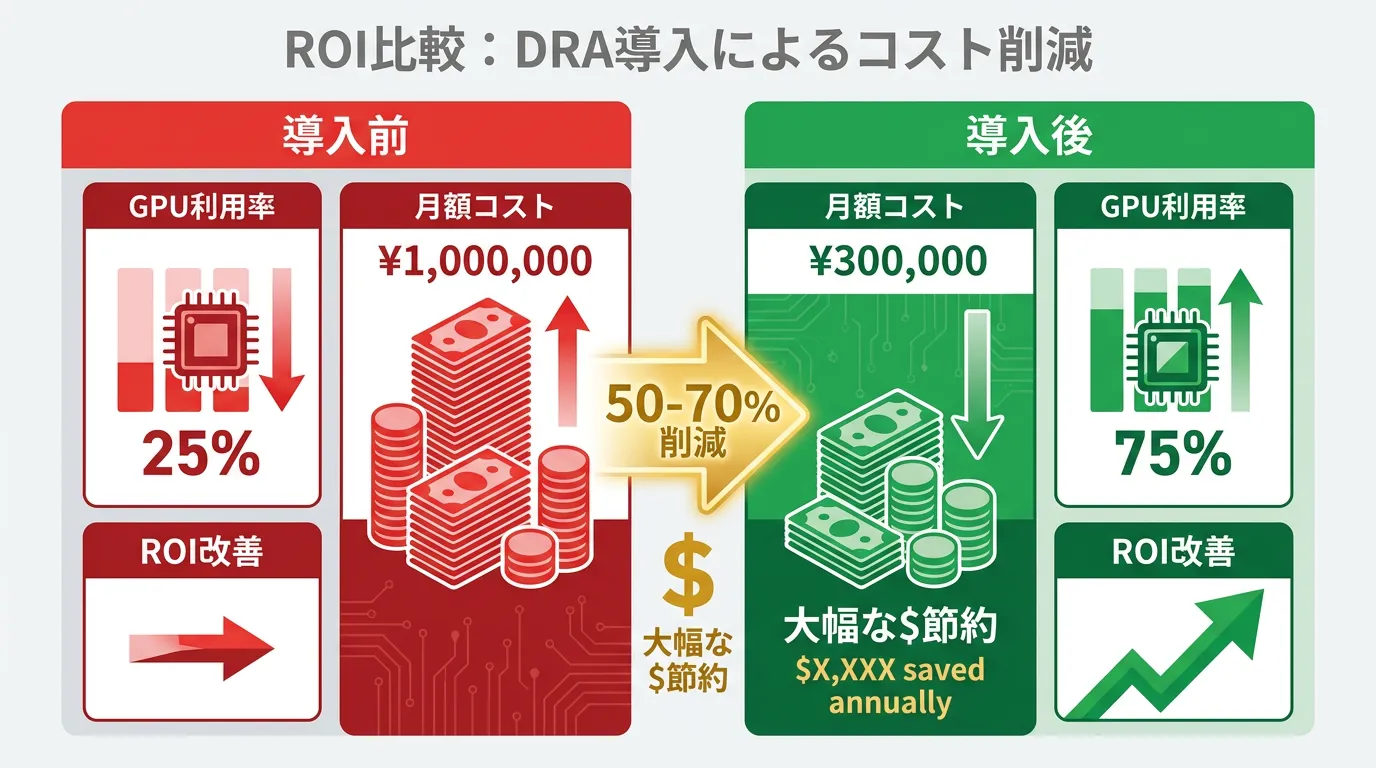
Concrete Cost Reduction Analysis
Using a monthly GPU utilization cost environment of $50,000 as an example:
| Item | Traditional Method | Post-DRA Implementation | Reduction Effect |
|---|---|---|---|
| GPU Utilization | 25% | 75% | 3x improvement |
| Required Instances | 12 units | 4 units | 67% reduction |
| Monthly Cost | $50,000 | $16,667 | $33,333 saved |
This achieves approximately $400,000 in annual cost reduction.
Enterprise Implementation Key Points
Companies successful with DRA implementation adopt phased migration strategies:
- PoC Phase: Small-scale validation with inference workloads
- Pilot Phase: Full implementation in development environments
- Full Deployment: Sequential migration in production environments
The AI-Driven Development Coaching Seminar provides opportunities to learn specific roadmap design techniques for DRA implementation strategies, offering practical knowledge acquisition for technical leaders.
'AI-Native Cluster' Design Supporting 2026's $5.7B AI Market Growth
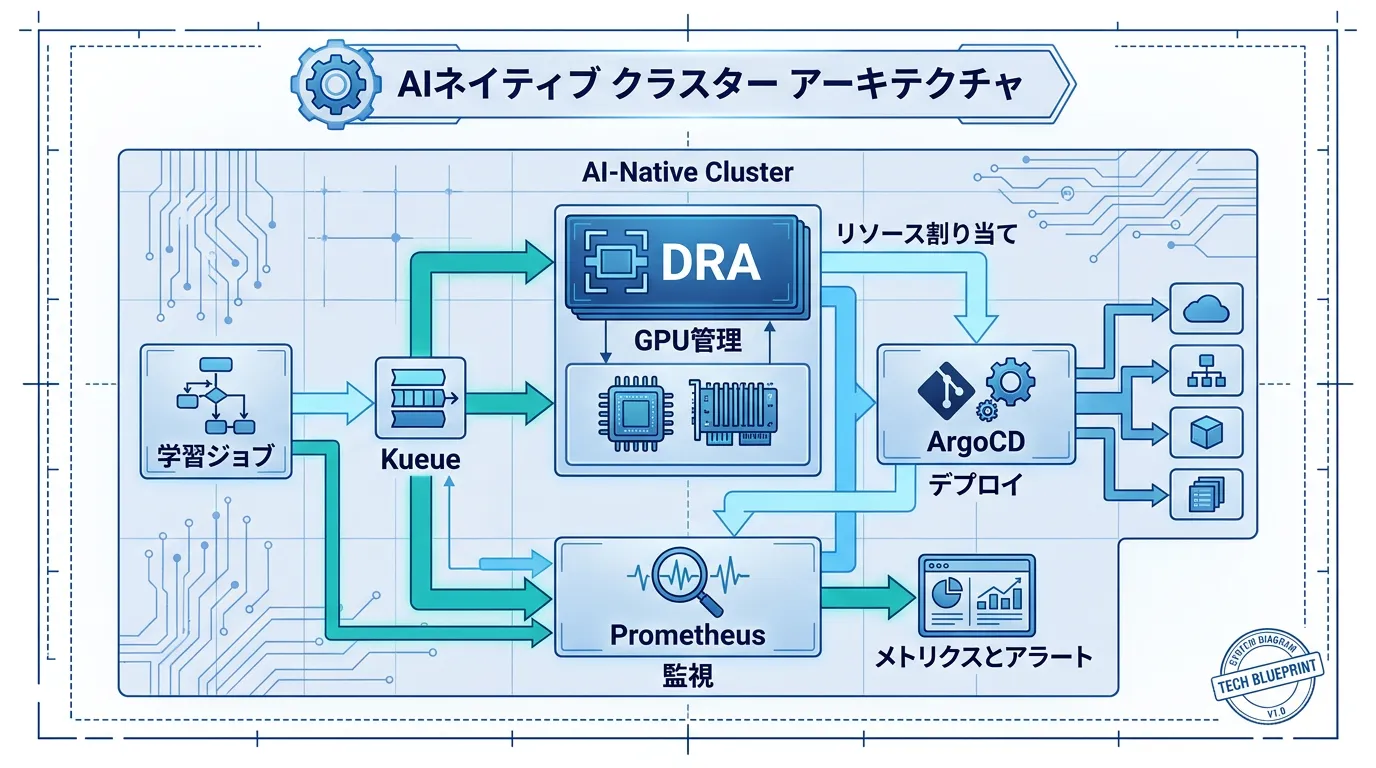
The Kubernetes for AI workloads market is projected to reach $5.7B in 2026, expanding at an 18.8% compound annual growth rate. This growth is supported by the "AI-native cluster" design philosophy.
Four Pillars of AI-Native Clusters
1. Dynamic Resource Allocation (DRA)
- Dynamic allocation of GPU/TPU resources
- Optimal resource distribution based on workload characteristics
2. Workload Orchestration
- Learning job queuing through Kueue
- Priority-based resource scheduling
3. GitOps Integration
- Automated model deployment via ArgoCD/Flux
- Inference API version management
4. Observability & Monitoring
- GPU metrics collection and visualization with Prometheus
- Cost tracking and resource efficiency monitoring
Implementation Architecture Patterns
# AI-native cluster configuration example
apiVersion: v1
kind: ConfigMap
metadata:
name: ai-cluster-config
data:
dra-config: |
deviceClasses:
training: high-memory-gpu
inference: shared-gpu
autoScaling: enabled
costOptimization: aggressive
Scalability Design
AI-native clusters adopt the following scaling strategies:
- Horizontal Scaling: Automatic node addition during workload increases
- Vertical Scaling: Dynamic adjustment of GPU memory/compute power
- Hybrid Scaling: Flexible combination of on-premises + cloud
Multi-tenant Support
Enterprise environments require multiple development teams to securely share the same cluster:
- Namespace-based Isolation: Team-specific resource separation
- NetworkPolicy: Secure communication control
- ResourceQuota: Fair resource allocation
Kubo provides AI-native cluster infrastructure that meets these enterprise requirements while maintaining K3s-based lightweight characteristics, starting from ¥48,000 per month, achieving significant cost advantages compared to AWS EKS (¥82,700) and Azure AKS (¥85,710).
Conclusion—Infrastructure Selection Criteria for the AI Co-work Era
In an era of AI collaboration, infrastructure selection has become a strategic decision that transcends simple cost comparison. Breaking free from the current state of 20-30% GPU utilization and achieving 70-80% efficiency through DRA-based dynamic resource management directly translates to maximizing AI investment ROI.
Criteria for Infrastructure Platform Selection
- Dynamic Resource Management Support: GPU efficiency through DRA compatibility
- AI Workload Optimization: Comprehensive support for training, inference, and fine-tuning
- Cost Transparency: Fixed pricing structure eliminating pay-as-you-go uncertainty
- Operational Automation: Reduced operational burden through AI-Driven Deployment
- Vendor Lock-in Avoidance: Open environment based on Pure Kubernetes
Next Steps
For technical leaders and DX executives considering AI-era infrastructure strategy, building Kubernetes AI infrastructure leveraging DRA is an unavoidable challenge.
To break free from traditional high-cost, low-efficiency GPU infrastructure and achieve 50-70% cost reduction, consider Kubo's managed Kubernetes platform. Starting from ¥48,000 per month, with free consultation supporting everything from ROI analysis to concrete implementation roadmaps.
What the AI Co-work era demands is not merely infrastructure as a tool, but a foundation for collaboration between AI agents and humans. The right infrastructure choice will determine your organization's AI adoption success.