AI開発の現場で「GPU料金が高すぎる」という悲鳴が聞こえませんか?実は、多くの企業のKubernetes AI ワークロードでGPU利用率がわずか20-30%という現実があります。これは、静的なリソース割り当てによる「金食い虫」インフラの典型例です。
しかし、CNCF Annual Cloud Native Survey(2026年)では、82%の組織がKubernetesをプロダクション環境で利用し、66%がAI推論ワークロードでKubernetesを活用していると報告されています。つまり、Kubernetesは既にAI時代の「デファクト・オペレーティングシステム」になっているのです。
本記事では、Kubernetes Dynamic Resource Allocation(DRA)による動的リソース管理で、50-70%のAIインフラコスト削減を実現する最新手法を解説します。
AI時代のGPU危機—利用率20%の『金食い虫』インフラ
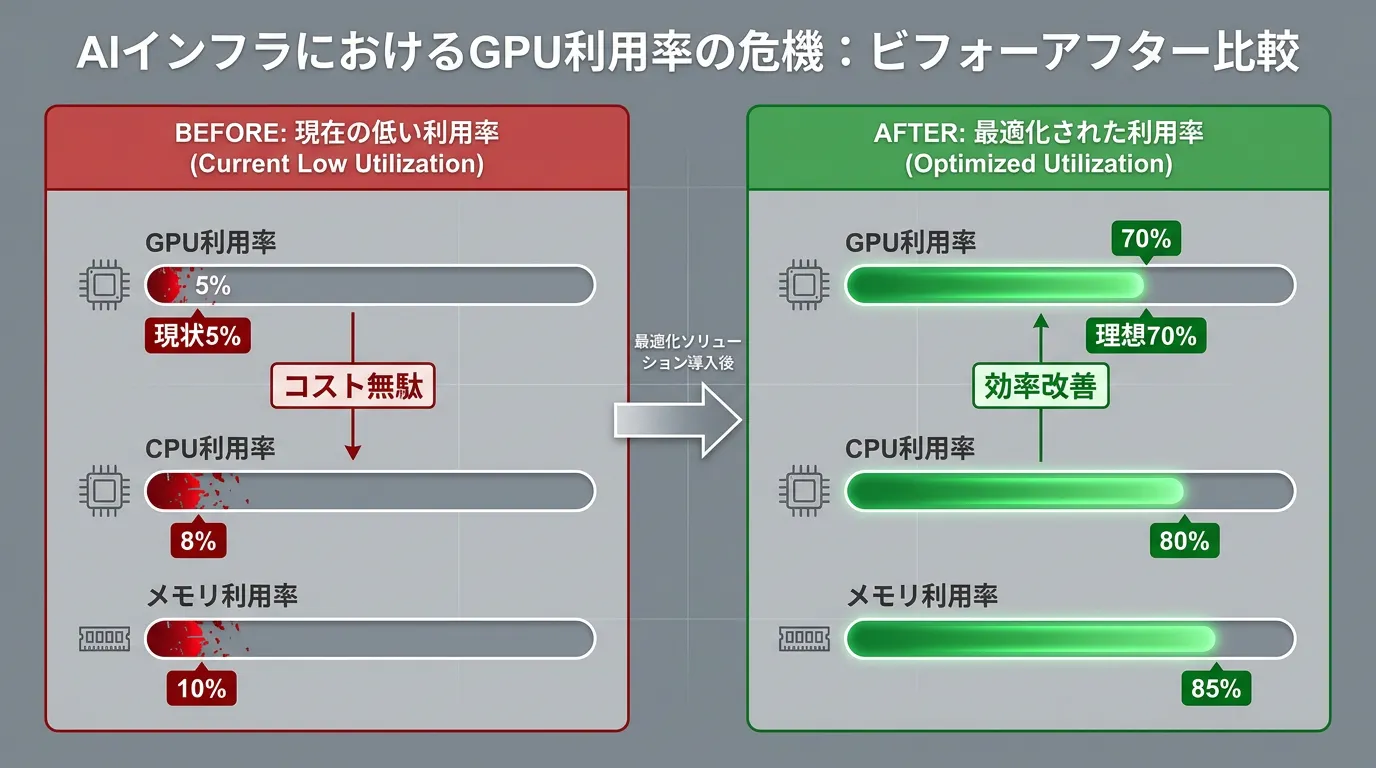
AI/MLワークロードのGPU利用率の現実は、想像以上に深刻です。Cast AI の2026年調査によると、23,000のKubernetesクラスター分析の結果、GPU利用率は平均わずか5%、CPU利用率も8%(前年の10%から低下)という結果が発表されました。
静的リソース割り当ての限界
従来のKubernetesでは、GPUリソースを静的に割り当てる「Device Plugin」方式が主流でした。この方式では以下の課題が顕在化しています:
- 過剰プロビジョニング: CPU過剰プロビジョニングが前年の40%から69%へ急増
- リソース固定化: 一度割り当てたGPUは他のワークロードで共有不可
- 粒度の粗さ: GPU全体での割り当てのみで、メモリ容量や計算能力での細分化ができない
- 調整コストの高さ: ワークロード変動に合わせた手動調整が必要
コスト圧迫の現実
AWS ではH200 Capacity Block の価格が2026年1月に15%上昇しており、5%の利用率でこの高コストを負担する現状は、企業のAI投資ROIを著しく悪化させています。
多くの企業が「AIプロジェクトはコストが見合わない」と判断する背景には、この根本的なリソース効率性の問題があるのです。コスト最適化を実現するには、従来の静的割り当てから脱却し、動的なリソース管理へ移行する必要があります。この課題に対する解決策として、KuboのようなマネージドKubernetes基盤では、AI-Driven Deploymentによるリソース最適化の自動化に取り組んでいます。
Kubernetes Dynamic Resource Allocation(DRA)が変える次世代GPU管理
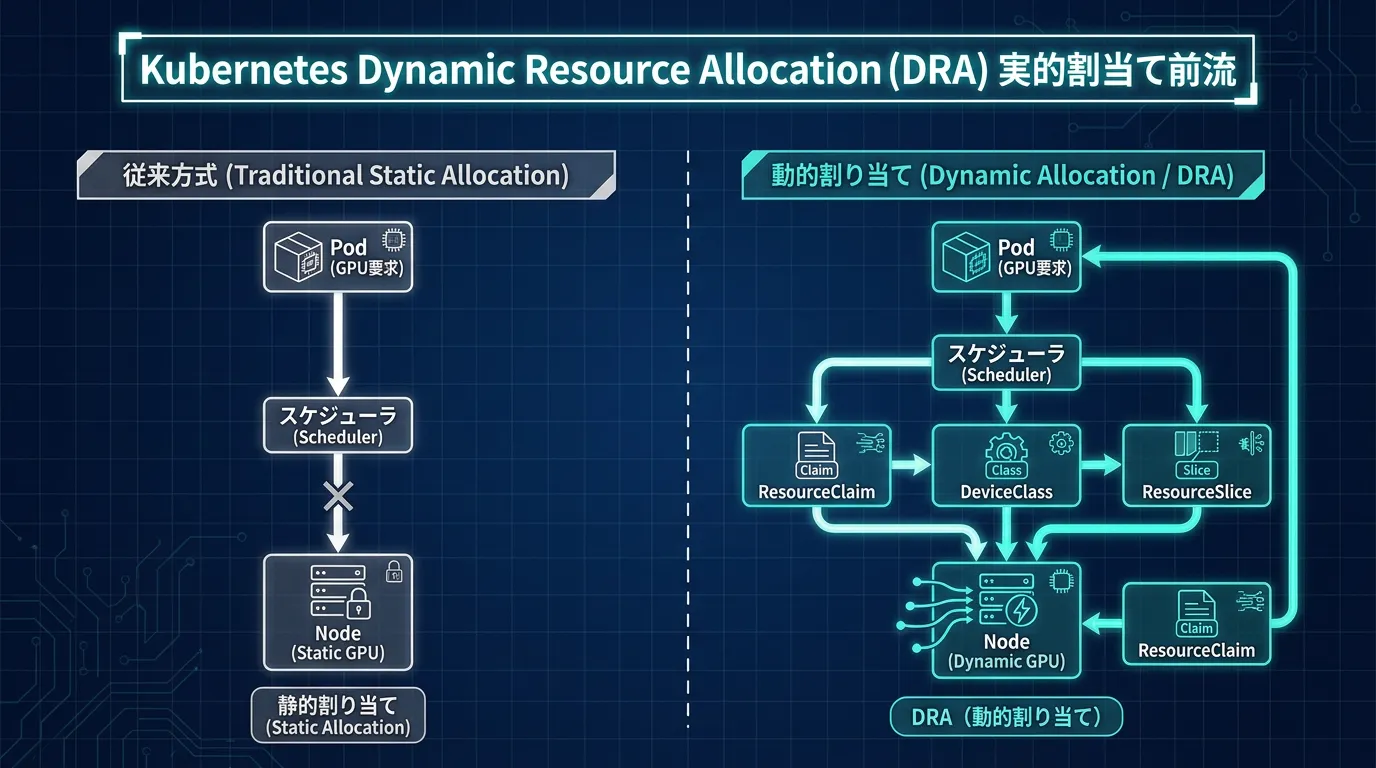
Kubernetes 1.34でGA(General Availability)に到達したDynamic Resource Allocation(DRA)は、従来の静的なDevice Plugin方式を置き換える革新的なアプローチです。
DRAの3つのコア革新
1. 宣言的リソース指定
DRAでは、「GPU 2個」ではなく「GPU メモリ8GiB以上、CUDA Compute Capability 8.0以上」のような具体的な要件をCommon Expression Language(CEL)で記述できます:
apiVersion: resource.k8s.io/v1
kind: ResourceClaim
metadata:
name: ai-gpu-claim
spec:
deviceClassName: high-performance-gpu
devices:
requests:
- name: training-gpu
selectors:
- matchExpressions:
- name: memory
operator: Gt
values: ["8Gi"]
- name: compute-capability
operator: Gte
values: ["8.0"]
2. デバイス共有とプール化
複数のコンテナやPodが同一のResourceClaimを参照でき、GPUの分割利用が可能になります。これにより、推論ワークロードでは複数のモデルで1つのGPUを効率的に共有できます。
3. 中央集約化された管理
DeviceClassによる集約的なデバイス分類により、クラスター管理者がワークロードタイプ別の最適なデバイス構成を事前定義できます。
従来方式との決定的な違い
| 項目 | Device Plugin(従来) | DRA(新方式) |
|---|---|---|
| リソース指定 | 数量ベース(GPU 2個) | 能力ベース(メモリ8GiB以上) |
| デバイス共有 | 不可 | 可能 |
| 動的最適化 | 手動調整が必要 | 自動的な最適配置 |
| 粒度 | GPU単位 | GPU内リソース単位 |
実証済み:70-80%GPU利用率で50-70%コスト削減事例
DRA技術の導入により、実際に大幅なコスト削減を達成した企業事例が増加しています。
利用率劇的改善の実績
先進的な企業では、DRAによる動的リソース管理で70-80%のGPU利用率を達成し、従来の20-30%から大幅改善しています。これは、以下の技術的改善によるものです:
自動リソース調整
- ワークロード需要に応じたリアルタイム GPU 配分
- アイドル時間の最小化
- 複数ワークロード間での効率的なGPU共有
インテリジェントスケジューリング
- Kubernetes スケジューラがResourceSliceを参照し、最適なノード配置を自動決定
- デバイス特性(メモリ容量、計算性能)を考慮した配置最適化
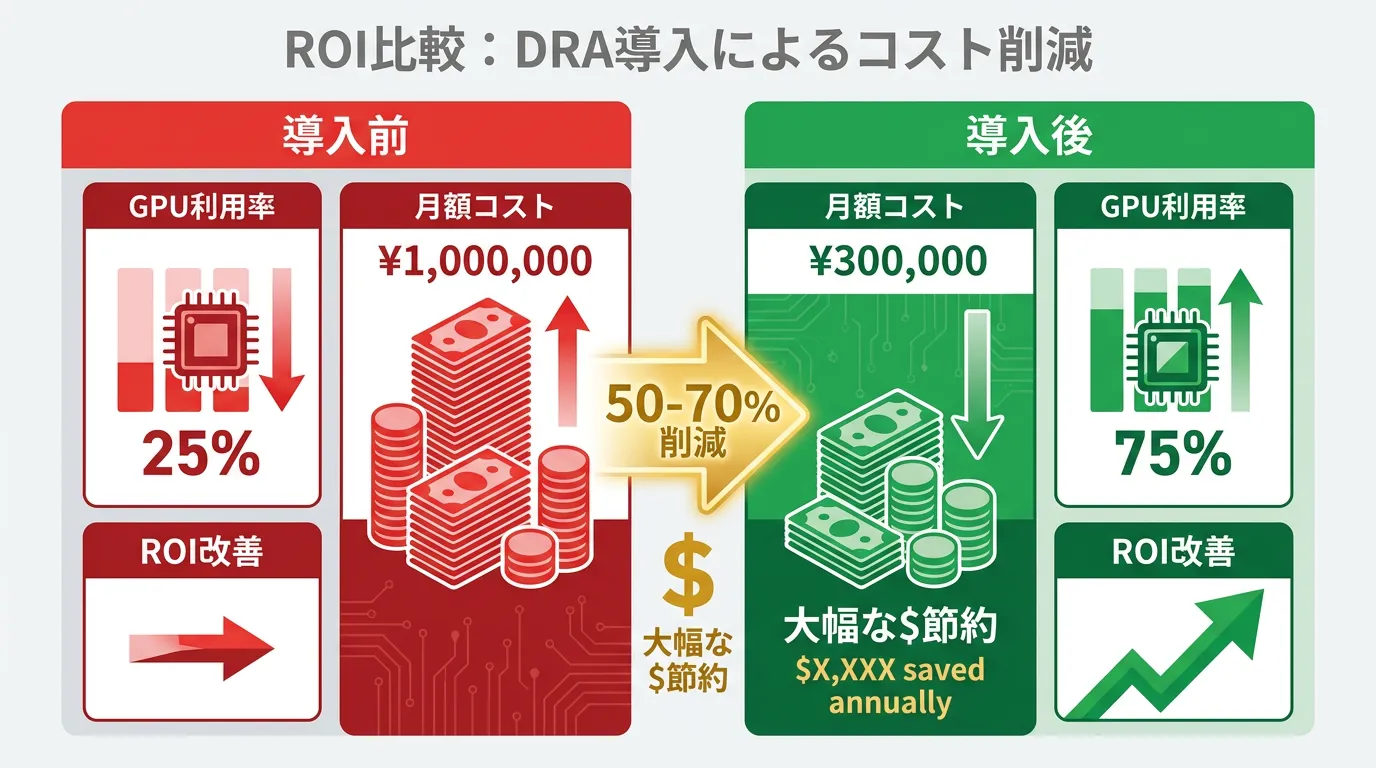
具体的コスト削減試算
月間GPU利用コスト $50,000 の環境を例にとると:
| 項目 | 従来方式 | DRA導入後 | 削減効果 |
|---|---|---|---|
| GPU利用率 | 25% | 75% | 3倍向上 |
| 必要インスタンス数 | 12台 | 4台 | 67%削減 |
| 月額コスト | $50,000 | $16,667 | $33,333削減 |
この結果、年間約$400,000のコスト削減を実現しています。
エンタープライズ導入の要点
DRAの導入成功企業では、段階的なマイグレーション戦略を採用しています:
- PoC段階: 推論ワークロードでの小規模検証
- パイロット段階: 開発環境での全面導入
- 本格展開: プロダクション環境での順次切り替え
AI駆動開発伴走セミナーでは、このようなDRA導入戦略の具体的なロードマップ設計手法を学ぶことができ、技術リーダーにとって実践的な知識習得の機会となっています。
2026年AI市場$5.7B成長を支える『AIネイティブクラスター』設計法
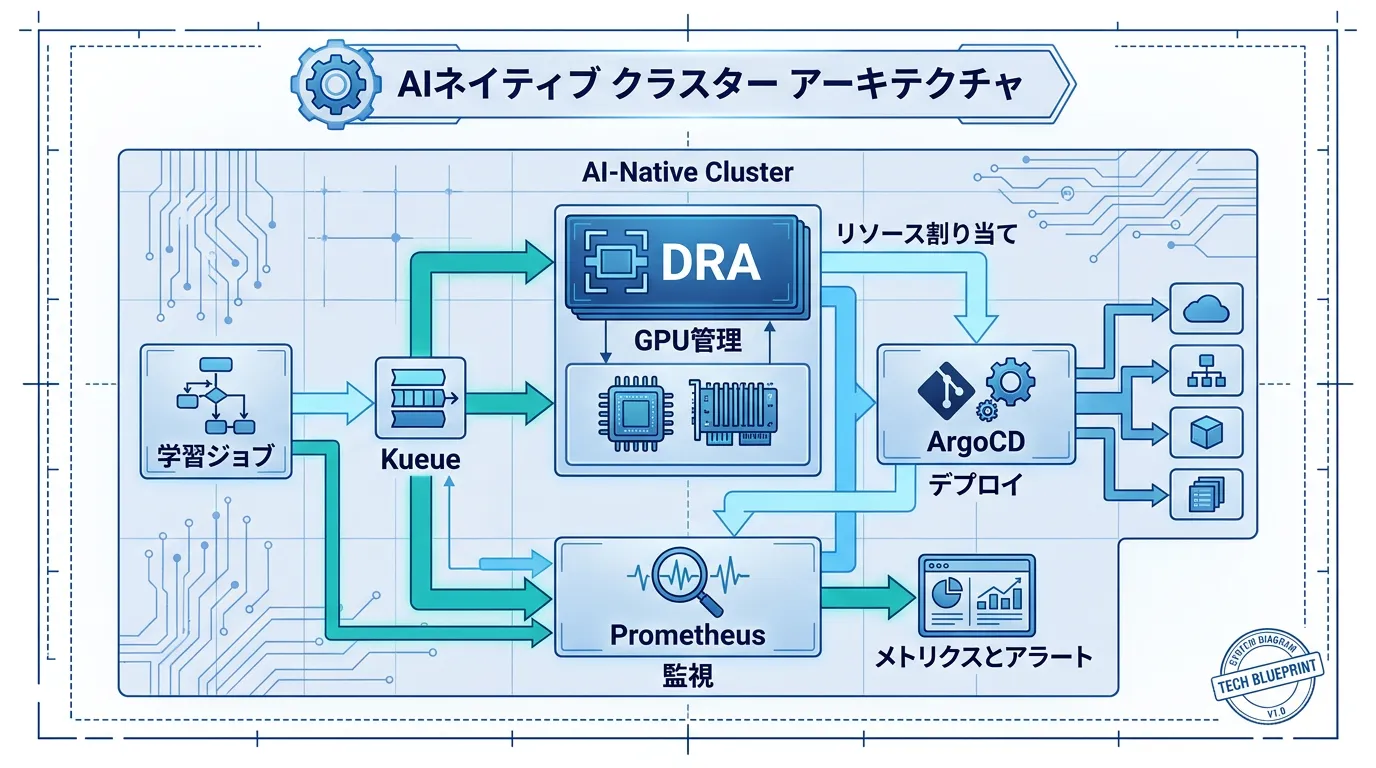
Kubernetes for AI workloads市場は2026年に$5.7Bに到達し、年平均成長率18.8%で拡大中です。この成長を支えるのが「AIネイティブクラスター」という設計思想です。
AIネイティブクラスターの4つの柱
1. Dynamic Resource Allocation(DRA)
- GPU/TPUの動的割り当て
- ワークロード特性に応じた最適リソース配分
2. Workload Orchestration
- Kueue による学習ジョブキューイング
- 優先度ベースのリソーススケジューリング
3. GitOps Integration
- ArgoCD/Fluxによるモデルデプロイメント自動化
- 推論APIのバージョン管理
4. Observability & Monitoring
- GPU メトリクス収集とPropheusによる可視化
- コスト追跡とリソース効率性監視
実装アーキテクチャパターン
# AIネイティブクラスター設定例
apiVersion: v1
kind: ConfigMap
metadata:
name: ai-cluster-config
data:
dra-config: |
deviceClasses:
training: high-memory-gpu
inference: shared-gpu
autoScaling: enabled
costOptimization: aggressive
スケーラビリティ設計
AIネイティブクラスターでは、以下のスケーリング戦略が採用されています:
- 水平スケーリング: ワークロード増加時の自動ノード追加
- 垂直スケーリング: GPU メモリ/計算力の動的調整
- ハイブリッドスケーリング: オンプレ+クラウドの柔軟な組み合わせ
マルチテナント対応
企業環境では、複数の開発チームが同一クラスターを安全に共有する必要があります:
- NamespaceベースIsolation: チーム別リソース分離
- NetworkPolicy: セキュアな通信制御
- ResourceQuota: 公平なリソース配分
Kuboは、K3sベースの軽量性を保ちながら、これらのエンタープライズ要件を満たすAIネイティブクラスター基盤を月額¥48,000から提供しており、AWS EKS(¥82,700)やAzure AKS(¥85,710)と比較して大幅なコスト優位性を実現しています。
まとめ—AI Co-workインフラの選択基準
AIと協働する時代において、インフラ選択は単なるコスト比較を超えた戦略的判断になっています。GPU利用率20-30%の現状から脱却し、DRAによる動的リソース管理で70-80%の効率化を実現することは、AI投資のROI最大化に直結します。
選択すべきインフラ基盤の条件
- 動的リソース管理対応: DRA対応によるGPU効率化
- AIワークロード最適化: 学習・推論・ファインチューニングの包括対応
- コスト透明性: 従量課金の不確実性を排除する固定料金体系
- 運用自動化: AI-Driven Deploymentによる運用負荷軽減
- ベンダーロックイン回避: Pure Kubernetesベースのオープン環境
次のアクション
AI時代のインフラ戦略を検討中の技術リーダーやDX推進担当者にとって、DRAを活用したKubernetes AI基盤の構築は避けて通れない課題です。
従来の高コスト・低効率なGPUインフラから脱却し、50-70%のコスト削減を実現したいなら、KuboのマネージドKubernetes基盤を検討してみてください。月額¥48,000からスタートでき、無料相談でROI試算から具体的な導入ロードマップまでサポートします。
AI Co-workの時代に求められるのは、単なるツールとしてのインフラではなく、AIエージェントと人間が協働するための基盤です。適切なインフラ選択が、あなたの組織のAI活用成功を左右するのです。